
Byte-Level Language Models Get a Speed Boost
Byte-level language models promise a future free from subword tokenization, handling noisy, multilingual, and structured inputs with grace. But they come at a cost: longer sequences mean higher compute and memory demands. Now, a team from Stanford University, University of Washington, and FAIR at Meta has unveiled a family of models that dramatically cuts these costs while maintaining performance. Their work, detailed in the preprint Fast Byte Latent Transformer (arXiv: 2605.08044v1), introduces three novel inference strategies that reduce memory-bandwidth usage by up to 92%.
"Our methods achieve over 50% lower memory-bandwidth cost than the standard Byte Latent Transformer, with up to 92% reduction when using larger blocks."
The Challenge of Byte-Level Processing
Byte-level models operate directly on raw bytes, sidestepping the brittleness of subword tokenizers. They are more robust to input noise, handle out-of-domain data better, and reduce disparities across languages. However, processing byte sequences—often thousands of tokens long—makes training and inference expensive. The Byte Latent Transformer (BLT) addressed this by grouping bytes into variable-length patches using entropy-based segmentation. High-entropy regions (e.g., rare words) get short patches, while predictable spans (e.g., common words) form longer ones. This hierarchical design reduces the sequence length by roughly a factor of four, but the autoregressive decoder still processes bytes one by one.
Three Routes to Faster Generation
The new work builds on the BLT architecture—comprising a local encoder, a global Transformer, and a local decoder—and introduces three complementary inference methods:
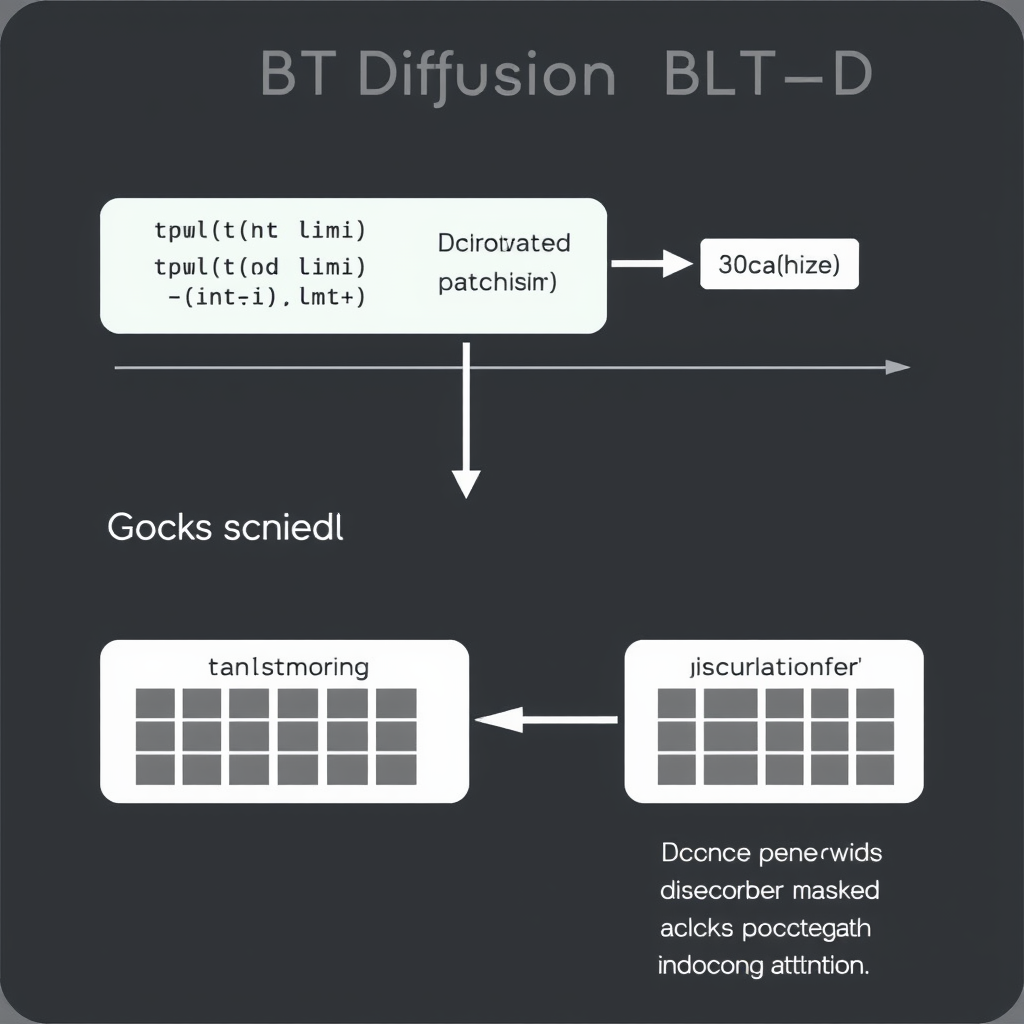
BLT Diffusion (BLT-D)
BLT-D replaces the autoregressive decoder with a block-wise discrete diffusion process. Instead of generating bytes one at a time, the model drafts an entire block of bytes in parallel using iterative denoising. During training, blocks of bytes are corrupted by masking with probability proportional to a noise level t, and the decoder learns to reconstruct the original bytes. At inference, a masked block is appended to the prefix, and the model unmaskes it in a few steps (fewer than the block size), using confidence-based or entropy-bounded strategies. This cuts the number of decoder forward passes per block from B to s < B.
BLT Self-Speculation (BLT-S)
Inspired by speculative decoding, BLT-S uses the lightweight local decoder to draft multiple bytes beyond the current patch boundary. The full model then verifies the draft in one pass, accepting a prefix of correct bytes. This guarantees at least one byte per step but often produces several, reducing the number of full model calls.
BLT Diffusion + Verification (BLT-DV)
BLT-DV combines the best of both: a diffusion draft of a full block, followed by an autoregressive verification pass. This recovers performance lost in pure diffusion, especially on code generation tasks, while still achieving up to 81% bandwidth reduction.
All three methods require no architectural changes or retraining—they are inference-time extensions of the standard BLT.
Model Sizes and Training Details
The team trained two model scales: 1B and 3B parameters. The table below summarizes the parameter counts and training configurations.
| Model | Global Params | Encoder Params | Decoder Params | Training Steps | Batch Size (tokens) |
|---|---|---|---|---|---|
| 1B | 1.28B | 19M | 160M | 240k | 2^19 (~2M bytes) |
| 3B | 2.82B | 26M | 160M | 480k | 2^20 (~4M bytes) |
All models use entropy-based patching with an average patch size of 4 bytes and a maximum of 8. Training employed AdamW with cosine learning rate scheduling, SwiGLU activations, RoPE positional encodings, and FlashAttention for efficient attention computation.
Performance and Efficiency Gains
On translation tasks (FLORES-101 French→English and German→English) and code generation (HumanEval, MBPP), the methods were evaluated at the 3B scale. The key metric is memory bandwidth, calculated as:
bandwidth = (N_dec * P_dec + N_enc * (P_enc + P_glob)) / 1e9
where N_dec and N_enc are the number of decoder and encoder/global forward passes, and P denotes parameter counts.
| Method | N_dec | N_enc | Bandwidth (GB) | Translation BLEU | Code pass@1 |
|---|---|---|---|---|---|
| BLT (baseline) | 1.0x | 1.0x | 1.0x (ref) | high | high |
| BLT-D-4 | <0.5x | 1.0x | <0.5x | ~match | slight drop |
| BLT-D-16 | <0.2x | 1.0x | 0.08–0.13x | competitive | lower |
| BLT-DV | ~0.3x | 1.0x | ~0.19x | recovered | recovered |
| BLT-S | ~0.5x | ~0.3x | ~0.23x | near baseline | near baseline |
BLT-D with block size 4 achieves a 50% reduction in decoder NFEs and bandwidth while matching BLT scores. With block size 16, bandwidth drops by 87–92% on translation, though code generation suffers. BLT-DV recovers code performance with up to 81% reduction, and BLT-S delivers up to 77% reduction with minimal quality loss.
Looking Ahead
The Fast Byte Latent Transformer paper demonstrates that byte-level models can be made practical for real-world deployment. By combining hierarchical latent tokenization with diffusion-based or speculative decoding strategies, the team has slashed the computational bottleneck without sacrificing quality. The methods are particularly attractive for multilingual and code generation applications, where subword tokenizers often struggle.
Future work may explore larger block sizes, adaptive block boundaries, and integration with other efficient attention mechanisms. For now, these results mark a significant step toward making byte-level language models a viable alternative to tokenizer-based systems.



