
When Should an AI Agent Ask for Help?
Long-horizon AI agents are designed to execute complex workflows that span hundreds of sequential actions. A single wrong assumption early in execution can cascade into irreversible errors. When instructions are incomplete, the agent must decide not only whether to ask for clarification but when. Until now, no prior work has measured how the value of clarification changes over the course of execution. A new paper, "Ask Early, Ask Late, Ask Right: When Does Clarification Timing Matter for Long-Horizon Agents?" (arXiv:2605.07937), fills that gap with a rigorous empirical framework.
A Forced-Injection Framework
The researchers introduced a novel forced-injection framework that provides ground-truth clarifications at controlled points in the agent's trajectory. They tested four information dimensions: goal, input, constraint, and context. Experiments were conducted across three agent benchmarks, using four frontier models (three models per benchmark, with one model used on a single benchmark only). In total, 84 task variants and over 6,000 runs were performed. This large-scale setup allowed the team to isolate the effect of timing from other variables.
Key Findings: Timing Is Everything
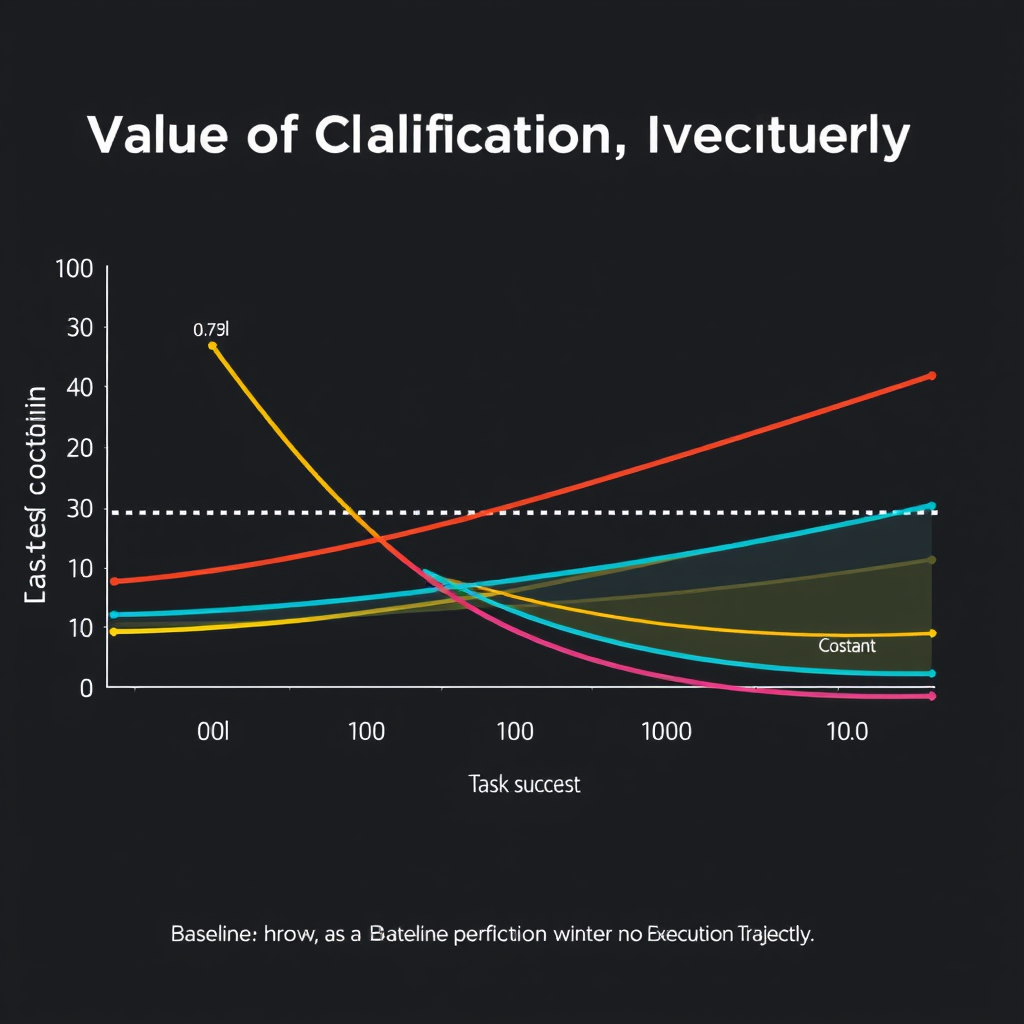
The value of clarification depends sharply on what information is missing. Goal clarification loses nearly all value after 10% of execution: pass@3 drops from 0.78 to baseline. In contrast, input clarification retains value through approximately 50% of execution. The most striking result: deferring any clarification type past mid-trajectory degrades performance below never asking at all.
"Deferring any clarification type past mid-trajectory degrades performance below never asking at all."
This suggests that late clarification is not just unhelpful—it actively harms the agent's performance, possibly by disrupting already established plans.
Cross-Model Consistency and Real-World Behavior
Kendall tau correlations among models sharing identical task coverage ranged from 0.78 to 0.87, confirming that timing profiles are substantially task-intrinsic. Across the full four-model panel, correlations dropped to 0.34–0.67, indicating some model-specific variation. A complementary study of 300 unscripted sessions revealed a sobering reality: no current frontier model asks within the empirically optimal window. Strategies ranged from over-asking (52% of sessions) to never asking at all. This mismatch between optimal timing and actual behavior underscores the need for better policies.
Conclusions and Contributions
The paper provides empirical demand curves that give quantitative foundation to existing theoretical frameworks. It establishes concrete design targets for timing-aware clarification policies. The authors have committed to releasing code and data publicly, enabling the community to build on their work. For developers of long-horizon agents, the message is clear: ask early, ask late, but above all, ask right.



