
Juggernaut Z by RunDiffusion
A cinematic fine-tune of Z-Image Base — tuned for presentation-ready output.
Juggernaut Z is a fine-tune of Z-Image Base by Team Juggernaut, trained by KandooAI, and released through RunDiffusion. It is tuned for stronger lighting, sharper focus, more refined skin texture, and more cinematic atmosphere — out of the box.
This repository hosts the official RunDiffusion release artifacts: full-precision weights, FP16 and FP8 variants, and a full set of GGUF quantizations.
Highlights
- More dramatic, cinematic lighting out of the box
- Sharper focus and a more deliberate camera feel
- Cleaner portraits with more natural skin texture
- Improved anatomy and structural integrity
- Better representation across ethnicities by default
- Tuned for editorial, concept, and cinematic work
Comparisons
All sets below show Juggernaut Z (left) vs Z-Image Base (right).
Lighting
More dramatic, cinematic lighting out of the box.






Skin & Texture
Cleaner, more natural-looking skin — especially in close-up portraits.
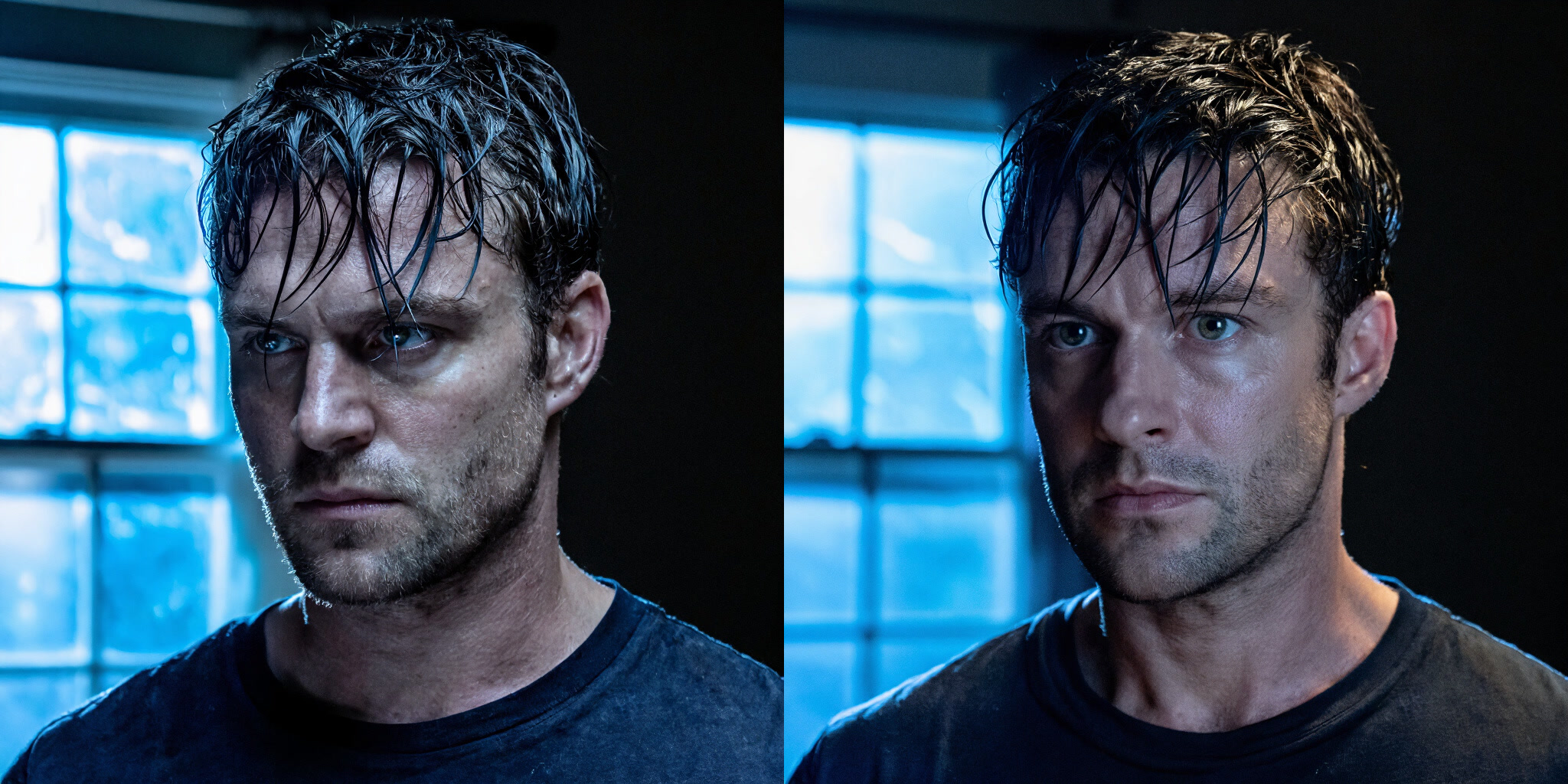



Anatomy
Cleaner anatomy and more consistent structural detail across a wide range of subjects.




Composition
Improved subject and object placement within scenes, with further work planned for v2.



Diversity
More balanced results across ethnic backgrounds, with better representation by default.
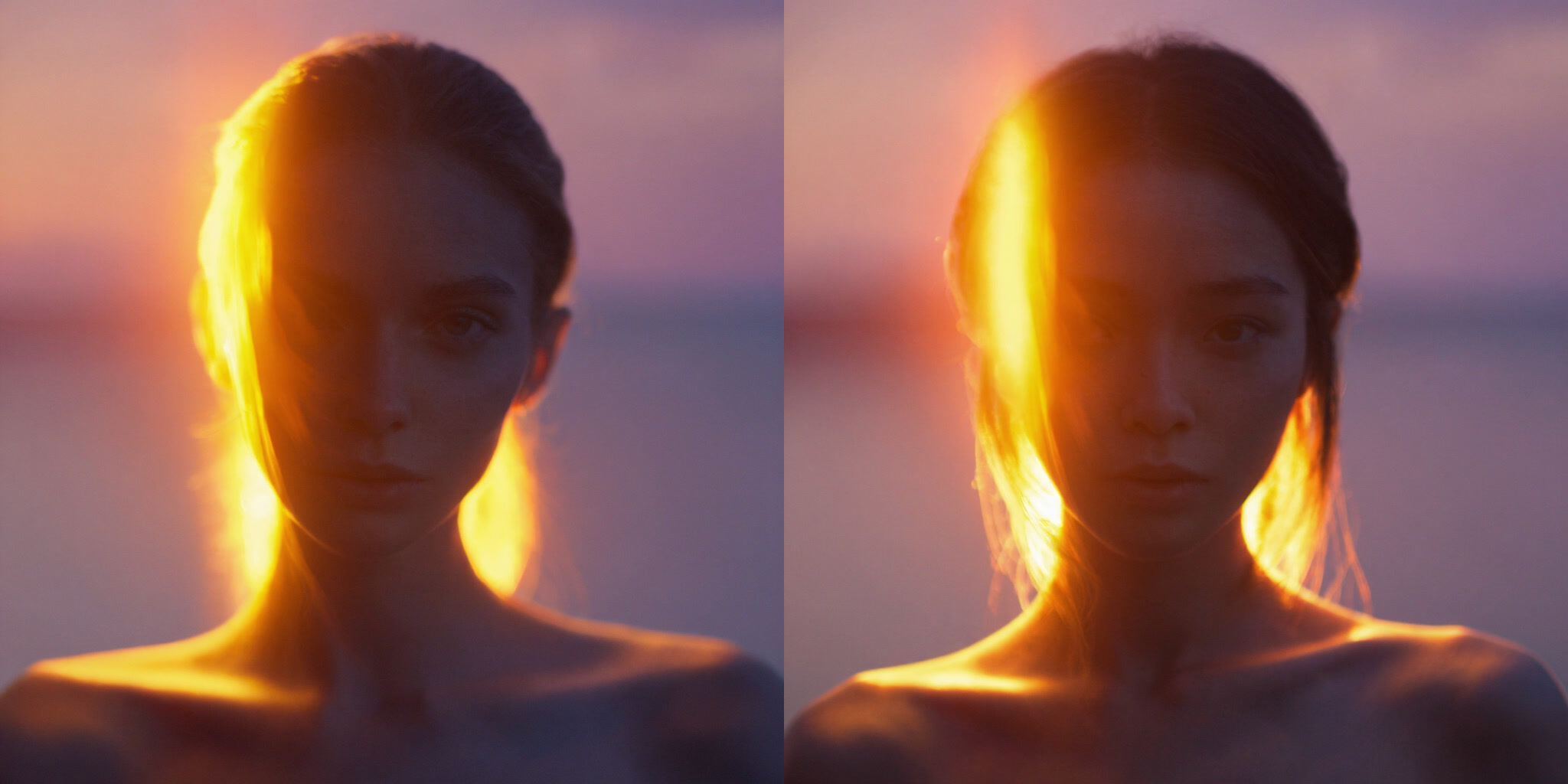



Architecture
Cleaner structural lines and more coherent material rendering.


Recommended Settings
| Parameter | Default | Range |
|---|---|---|
| CFG | 6 | 6 – 9 |
| Steps | 35 | 25 – 45 |
Files In This Repo
| File | Format | Notes |
|---|---|---|
Juggernaut_Z_V1_by_RunDiffusion.safetensors | safetensors (bf16) | Original release weights |
Juggernaut_Z_V1_by_RunDiffusion_fp16.safetensors | safetensors (fp16) | Half-precision |
Juggernaut_Z_V1_FP8_e4m3fn.safetensors | safetensors (fp8 e4m3fn) | Lower VRAM footprint |
Juggernaut_Z_V1_by_RunDiffusion_q8_0.gguf | GGUF · q8_0 | Highest-quality quant |
Juggernaut_Z_V1_by_RunDiffusion_q6_k-004.gguf | GGUF · q6_k | |
Juggernaut_Z_V1_by_RunDiffusion_q5_k_m-003.gguf | GGUF · q5_k_m | |
Juggernaut_Z_V1_by_RunDiffusion_q5_k_s-005.gguf | GGUF · q5_k_s | |
Juggernaut_Z_V1_by_RunDiffusion_q4_k_m-002.gguf | GGUF · q4_k_m | |
Juggernaut_Z_V1_by_RunDiffusion_q4_k_s-001.gguf | GGUF · q4_k_s | Smallest footprint |
model_index.json + transformer/, text_encoder/, tokenizer/, vae/, scheduler/ | 🤗 Diffusers format | Loaded by DiffusionPipeline.from_pretrained("RunDiffusion/Juggernaut-Z-Image") |
Use the .safetensors variants with the workflow that matches your local inference stack. Use the .gguf variants with a GGUF-compatible runtime. Use the Diffusers component layout with the 🤗 Diffusers library — see below.
Use with 🤗 Diffusers
The repo includes model_index.json and the standard 🤗 Diffusers component directories (transformer/, text_encoder/, tokenizer/, vae/, scheduler/) at the root, exported as a ZImagePipeline. Load it with:
from diffusers import DiffusionPipeline import torch pipe = DiffusionPipeline.from_pretrained( "RunDiffusion/Juggernaut-Z-Image", torch_dtype=torch.bfloat16, ).to("cuda") image = pipe( "a cinematic portrait, dramatic lighting", guidance_scale=6.0, num_inference_steps=35, ).images[0] image.save("output.png")
from_pretrained only downloads files declared in model_index.json, so it will not pull the standalone .safetensors / .gguf variants at the repo root. Requires a version of diffusers that includes ZImagePipeline support (verified against diffusers 0.37.1 and 0.38.0).


